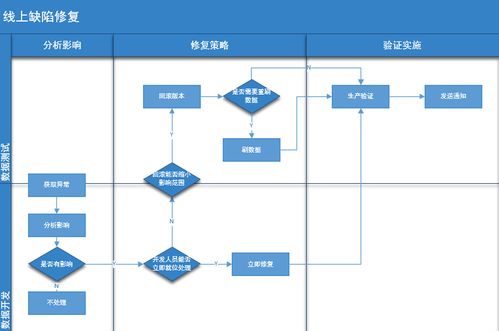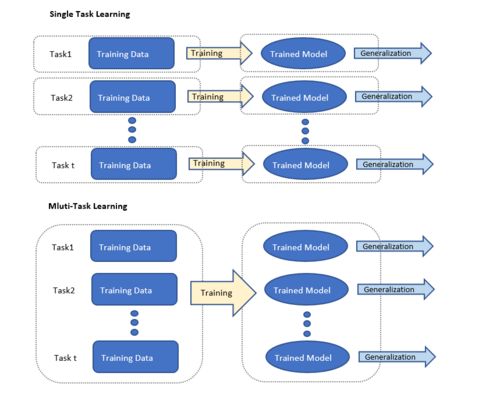
随着人工智能技术的飞速发展,多任务学习(Multi-Task Learning, MTL)已成为AI领域的重要研究方向。当AI实现多任务学习时,它能够通过共享知识处理多个相关任务,显著提升了大数据信息处理服务的效率和智能化水平。本文将探讨AI多任务学习的基本原理,以及它在大数据信息处理中的具体应用和潜力。
多任务学习是一种机器学习范式,允许模型同时学习多个任务,而不是孤立地处理每个任务。其核心思想是任务之间的知识共享:通过共享底层表示或参数,模型可以提取通用特征,从而在多个任务上取得更好的性能。例如,在自然语言处理中,一个多任务学习模型可以同时执行文本分类、情感分析和命名实体识别,因为这些任务都依赖于对语言结构的理解。
在大数据信息处理服务中,AI多任务学习展现出广泛的应用前景。大数据时代,信息量呈爆炸式增长,涉及文本、图像、视频等多种模态数据。传统处理方法往往需要为每个任务单独构建模型,导致资源浪费和效率低下。而多任务学习AI可以通过一个统一模型处理多个任务,显著降低计算成本和存储需求。具体来说,它可以在以下场景中发挥重要作用:
- 智能推荐系统:多任务学习模型可以同时优化点击率预测、用户留存分析和内容分类等任务,提供更精准的个性化推荐,提升用户体验和商业价值。
- 金融风控与欺诈检测:在金融大数据中,模型可以并行处理信用评分、交易异常检测和反洗钱分析,通过共享风险特征,提高整体检测准确性和响应速度。
- 医疗健康数据分析:AI可以同时进行疾病诊断、药物反应预测和患者风险评估,利用多任务学习整合电子病历、基因组数据和影像数据,辅助医生制定个性化治疗方案。
- 智能客服与情感分析:在处理海量用户反馈时,多任务模型能同时执行意图识别、情感分析和问题分类,快速提供高效服务,同时优化客户满意度。
- 物联网数据管理:在工业物联网中,多任务AI可并行监控设备状态、预测维护需求和优化能源消耗,实现对大数据流的实时处理和分析。
多任务学习的优势在于其泛化能力和效率提升。通过知识迁移,模型在数据稀疏的任务上也能表现良好,这对于大数据中常见的长尾问题尤为关键。它减少了模型冗余,加快了训练和推理速度,符合大数据处理对实时性的要求。
多任务学习也面临挑战,如任务冲突和负迁移问题——即某些任务可能相互干扰,导致性能下降。随着自适应权重分配和任务关系建模等技术的进步,AI多任务学习将更加成熟,推动大数据信息处理服务向更智能、更集成化的方向发展。
AI实现多任务学习为大数据信息处理服务带来了革命性变革。它不仅提升了处理效率和准确性,还开辟了新的应用场景,从企业决策到日常生活,无处不在。随着技术的不断迭代,我们有理由相信,多任务学习将成为驱动大数据智能化的核心引擎,助力社会迈向更加智慧的未来。